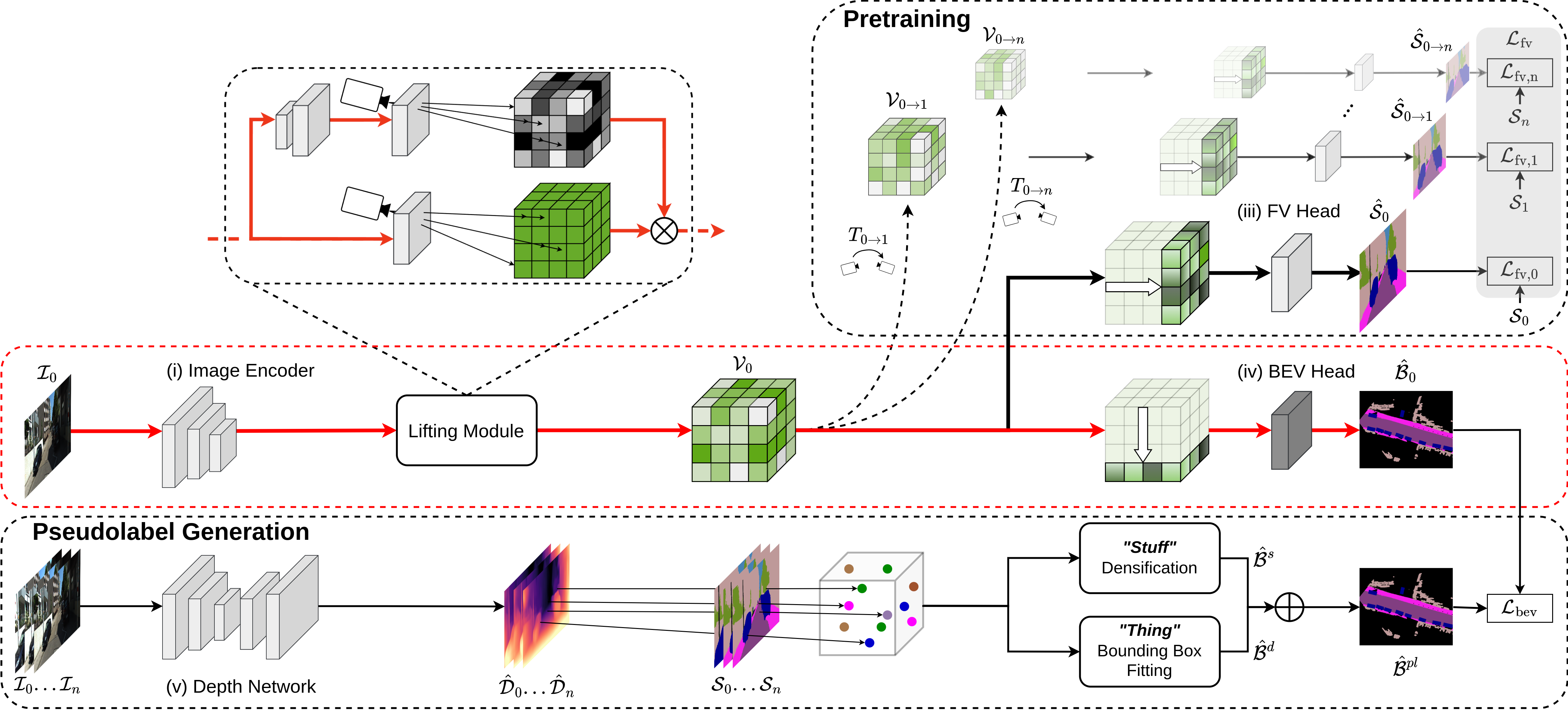
The goal of our SkyEye framework is to generate instantaneous BEV semantic maps without relying on any ground truth supervision in BEV. The core idea behind our approach is to generate an intermediate 3D voxel grid that serves as a joint feature representation for both FV and BEV segmentation. This joint representation allows us to leverage ground truth supervision in FV to augment the BEV semantic learning procedure.
Our SkyEye framework comprises five major components - (i) an image encoder to generate 2D features from the input monocular RGB image, (ii) a lifting module to generate the 3D voxel grid using a learned depth distribution, (iii) an FV semantic head to generate the FV semantic predictions, (iv) a BEV semantic head to generate the instantaneous BEV semantic map, and (v) an independent self-supervised depth network to generate the BEV pseudolabels.
The encoder employs an EfficientDet-D3 backbone to generate four feature scales from an input RGB image, which we subsequently merge to generate a composite 2D feature map.
The lifting module lifts the 2D features to a 3D voxel grid representation using the camera projection equation coupled with a learned depth distribution that provides the likelihood of features in a given voxel.
We then process the voxel grid depth-wise or height-wise to generate the output in FV or BEV, respectively.
The self-supervised depth network is independent of the aforementioned model and is only used to generate the BEV semantic pseudolabels. It follows the strategy outlined in Monodepth2 but replaces the default backbone with an EfficientDet-D3 backbone.